5월에 gggkik와 랜덤으로 뽑은 문제를 풀다가 나온 문제이다. 장장 3일 동안 고민했을 만큼 매우 어려운 문제라고 생각한다. 여담으로 gggkik는 잠깐 고민하더니 모르겠다고 도망갔다.. 꽤 좋은 문제라고 생각해서 블로그 글을 작성하려고 했는데, 풀이를 설명할 엄두가 나지 않아서 이제서야 작성한다. 문제는 매우 간단하다. $swap$ 연산으로 선택 정렬을 구현한 의사 코드가 주어지고, $N$개의 수에 대해 $M$번째 원소까지 선택 정렬을 수행했을 때의 $swap$ 연산 횟수를 출력하면 된다.
먼저, 몇 번의 시뮬레이션을 통해 어떤 규칙이나 패턴이 있는지 파악해 보자.
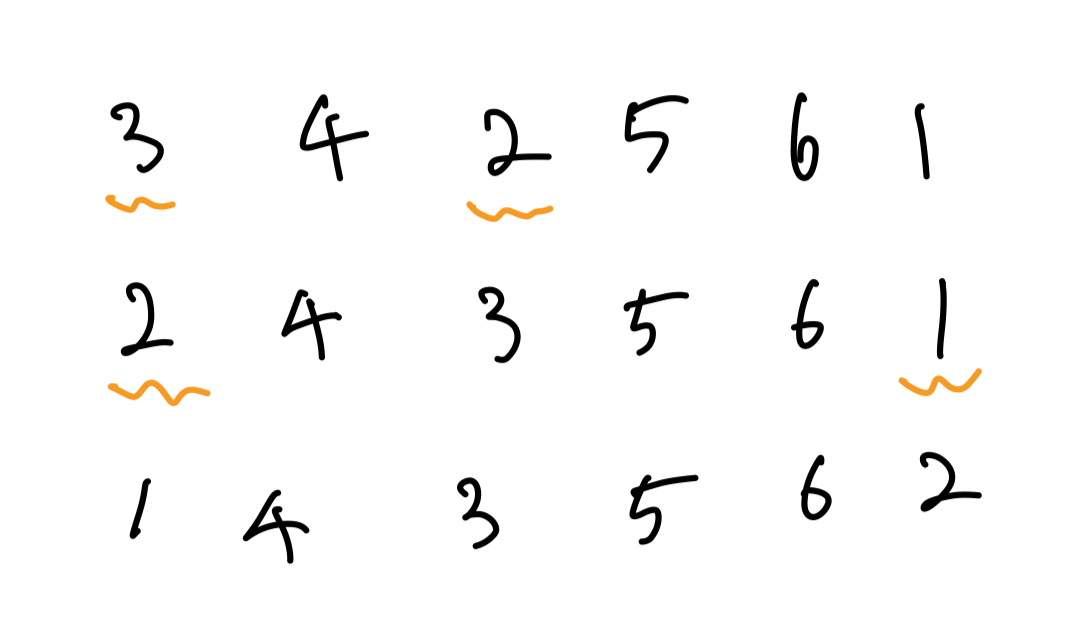
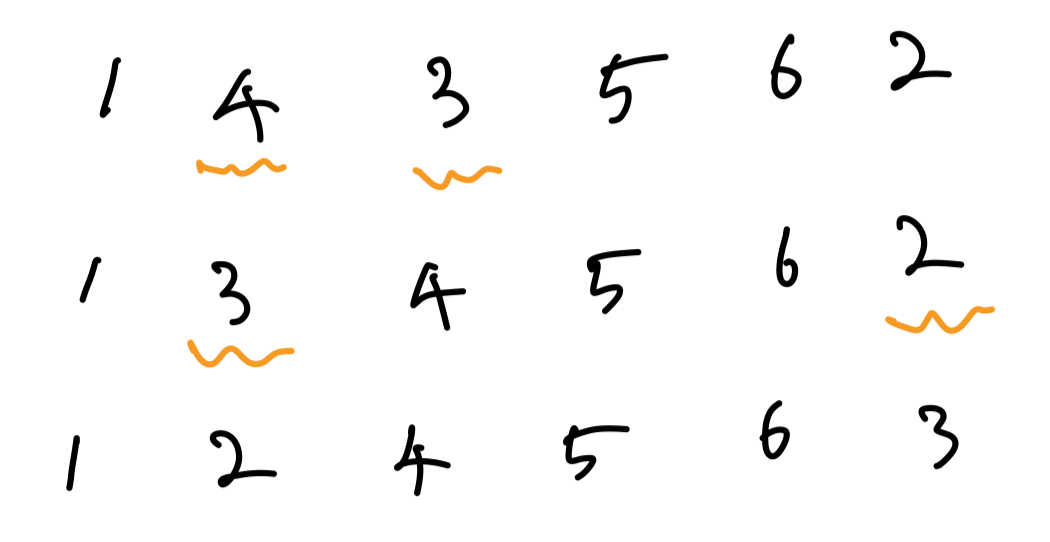
어떤 $i$에 대한 연산이 일어나기 전 처음 수열과 마지막 수열을 비교해 보자.


전체 수열을 $A$, 연산에 참여한 수로만 이루어진 $A$의 부분수열을 $S$라 하자. 한 번의 연산은 $S$를 1만큼 shift하는 것과 동치이다. 따라서, 모든 수는 자신의 차례가 오기 전에는 위치가 절대 앞으로 이동하지 않는다는 것을 알 수 있다. 또한, 선택 정렬의 성질로 인해 $S$는 $i$번째 칸의 수로 시작하는 strictly decreasing subsequence임을 알 수 있다.
$S$에 속하는 이웃한 두 수 $u, v$가 있다고 하자. $S$의 성질로 인해 $u > v$이다. 이때, $A$에서 $u$와 $v$ 사이에는 $u$보다 작은 수가 존재하지 않는다. 만약 $u$와 $v$ 사이에 $u$보다 작은 수 $w$가 존재했다면, $u$와 이웃한 수는 $v$가 아니라 $w$가 되어야 하므로 불가능하다. 따라서 연산 과정에서 $v$가 정렬되기 이전에 $u$와 $v$의 순서는 유지된다. 즉, 어떤 수 $u$의 오른쪽에 있고 $u$보다 작은 모든 수는 정렬되기 전에는 $u$의 왼쪽으로 이동하는 것이 불가능하다.
위 관찰들을 토대로 $swap$이 일어나는 횟수를 더 큰 수의 관점에서 셀 것이다. $swap$ 연산이 일어난 횟수는 $\sum (\vert S \vert - 1)$이므로 어떤 인덱스 $x$에 대해 $A_y < A_x$인 $y$가 있으면, $y$가 정렬될 때 생성되는 배열인 $S_y$에 $x$가 포함되는 횟수의 합이 전체 답이 될 것이다.
$x$가 $S_y$에 포함되지 않는 경우에 대해 생각해 보자. $x$의 왼쪽에 $x$보다 작은 수가 존재하는 경우에 $x$는 $S_y$에 포함되지 않을 것이다. 이때, $x$보다 왼쪽에 있고 $x$보다 작은 정렬되지 않은 수들의 집합을 $L_x$이라 하자. 만약 $y$가 $x$의 왼쪽에 있었다고 생각해 보자. 정렬되지 않은 수들 중 $y$가 최솟값이므로 $S_y$에 $x$ 오른쪽에 있는 수가 들어가는 것은 불가능하다. 따라서 $\vert L_x \vert$가 1 감소한다. 이제 $y$가 $x$의 오른쪽에 있지만 $x$의 왼쪽에 $x$보다 작은 수가 존재해 $x$가 포함되지 않는 상황을 보자. 연산은 $S_y$를 한 번 shift하는 것과 동치이므로 $x$의 오른쪽에 있고 $x$보다 작은 수들 중 $y$가 빠져나가고 $x$보다 왼쪽에 있고 $x$보다 작은 수 하나가 $x$의 오른쪽으로 넘어올 것이다. 마찬가지로 $\vert L_x \vert$가 1 감소한다.
위 결과에 따라 $L_x$가 공집합이 되기 전에는 $x$가 연산에 절대 참여할 수 없으며, $x$보다 작은 수가 하나 정렬될 때마다 $\vert L_x \vert$가 1 감소한다는 것을 알 수 있다. 연산이 최대 $M$번 진행되므로 $x$가 $S_y$에 포함되는 횟수는 $max(0, min(\vert \{t | t < x\} \vert, M) - \vert L_{x0} \vert)$이다. 구현은 수를 오름차순으로 정렬하고 세그먼트 트리를 이용하면 어렵지 않다.
하지만 여기서 반례가 존재하는데, 중복하는 수들이 있는 경우이다. 만약 수열이 $ \{ 2, 2, 1\}$와 같다면, 같은 수들이 $swap$될 일은 없기 때문에 1을 정렬하는 과정에서 발생하는 답은 1이지만 위 풀이는 각각의 2에서 1번씩 세어 버려 2가 나오게 된다.
먼저 중복되는 수들의 성질을 살펴 보자. 당연하게도 중복되는 수들은 절대 $swap$되지 않는다. 앞선 상황과 같이 $S$에 속하는 이웃한 두 인덱스 $i, j$가 있다고 하자. 그리고 $A$에서 $A_k = A_i$인 $k$가 있다고 하자. $k < i$인 경우, $S$에 $i$ 대신 $k$가 들어가야 하므로 불가능하다. $i < k < j$인 경우, 연산 후의 순서는 $A_k, A_i, A_j$순으로 변경된다. $A_k = A_i$이고, $A$에서 $i$와 $k$ 사이에 $A_i$보다 작은 수가 있는 것은 불가능하므로 연산 전후 항상 $L_i = L_k$이다. 또한, $i$와 $k$ 사이에 $A_i$보다 작은 수가 추가되는 것은 불가능하므로 연산이 진행됨에 따라 $i$와 $k$의 위치가 번갈아가면서 바뀔 것이며, $L_i = L_k$는 유지될 것이다. 마지막으로 $j < k$인 경우, 연산 후 $A_i, A_k$의 순서는 변하지 않는다.
위 결과에 따라 같은 값을 갖는 인덱스 여러 개가 존재할 때, 계산에 반영되어야 하는 $L$은 항상 가장 앞에 있는 원소의 $L$이라는 것을 알 수 있다. 또한, 몇 번째 연산까지 진행되었는지에 관계 없이 가장 앞에 있는 수의 $L$은 초기 배열에서 가장 앞에 있었던 원소의 $L$과 같음을 알 수 있다. 따라서 구현할 때 초기 배열에서 가장 앞에 있는 수의 $\vert L \vert$을 이용해서 계산하면 된다. 이때, $L$ 내부에 중복 원소가 들어 있을 때의 계산은 기존과 동일하기 때문에 세그먼트 트리에 더해 줄 때는 모든 인덱스에 더해 주어야 한다.
전체 코드와 테스트케이스 생성기, 도움이 되었던 테스트케이스들이다.
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
using pll = pair<ll, ll>;
inline void init() {
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
}
class fenwick {
private:
ll n;
vector<ll> tree;
public:
fenwick(ll n) : n(n), tree(n + 1) {}
void update(ll idx, ll val) {
for (idx++; idx <= n; idx += idx & -idx) tree[idx] += val;
}
ll sum(ll x) {
ll ret = 0;
for (x++; x > 0; x -= x & -x) ret += tree[x];
return ret;
}
ll sum(ll s, ll e) {
return sum(e - 1) - sum(s - 1);
}
};
int main() {
init();
ll n, m;
while (cin >> n >> m) {
vector<ll> a(n);
vector<pll> v(n);
ll ans = 0;
fenwick fw(n);
for (ll i = 0; i < n; i++) {
cin >> a[i];
v[i] = {a[i], i};
}
sort(v.begin(), v.end());
for (ll i = 0, e = 0; i < n; i = e) {
auto [val, idx] = v[i];
while (e < n and v[e].first == val) e++;
ans += max(0LL, min(m, i) - fw.sum(0, idx));
for (ll j = i; j < e; j++) {
fw.update(v[j].second, 1);
}
}
cout << ans << '\n';
}
return 0;
}#include <bits/stdc++.h>
using namespace std;
using ll = long long;
int main() {
int T = 5;
std::mt19937_64 rng(std::random_device{}());
auto rnd = [&](ll lo, ll hi) -> ll {
return std::uniform_int_distribution<ll>(lo, hi)(rng);
};
for (ll tc = 0; tc < T; tc++) {
ll n, m;
vector<ll> a;
n = rnd(1, 30);
m = rnd(1, n);
a.resize(n + 1);
for (int i = 1; i <= n; i++) {
a[i] = rnd(-1, 100);
}
cout << n << ' ' << m << '\n';
for (int i = 1; i <= n; i++) {
cout << a[i] << ' ';
}
cout << '\n';
}
return 0;
}
3 3
27 13 14
9 1
25 14 27 18 10 19 3 18 14
6 5
19 20 20 10 27 9
4 3
7 26 6 2
10 1
15 18 2 17 18 30 0 8 2 28
2
3
6
5
2
16 15
5 48 29 93 26 51 35 39 16 42 17 99 59 98 78 87
3 1
46 53 4
27 15
36 78 72 9 50 34 9 18 92 90 57 80 4 58 43 100 51 23 77 33 78 9 37 10 42 42 2
11 9
30 48 38 51 34 36 72 0 2 59 43
2 1
61 38
22 11
81 21 94 50 47 69 9 89 69 99 77 71 99 69 67 3 32 91 60 89 87 5
20 4
54 86 95 72 38 15 65 7 1 -1 8 31 82 38 1 50 43 29 65 1
12 4
22 27 81 71 44 61 62 8 19 70 45 58
19 8
65 51 1 100 38 63 97 33 48 18 13 72 84 37 27 28 59 57 93
21 1
69 84 47 76 2 99 48 51 94 18 52 44 1 53 92 67 81 67 76 18 12
38
1
129
25
1
63
27
11
47
3
# 모두 다름
15 15
99 97 47 55 30 43 100 72 83 1 68 73 53 62 13
11 6
30 75 51 11 27 50 15 53 94 37 35
19 2
54 12 3 99 33 89 75 64 42 68 79 93 23 77 60 25 19 96 72
13 9
46 84 74 81 69 42 58 90 75 88 15 52 24
22 17
41 7 43 91 23 88 54 74 61 82 22 48 27 66 85 30 56 10 90 42 94 45
24 8
33 63 61 68 93 2 21 98 65 100 12 92 78 89 5 52 69 75 57 48 45 55 60 95
28 21
60 55 42 17 70 23 28 7 3 94 57 14 43 12 99 91 48 96 69 29 27 90 33 85 82 45 83 61
11 11
57 11 62 80 35 23 83 100 60 91 66
11 8
43 2 15 77 62 21 80 31 28 71 61
26 4
78 23 54 72 21 46 56 100 6 0 60 32 11 66 30 15 3 73 25 12 91 29 58 90 63 43
65
18
3
41
96
39
134
17
18
23

